![[Diagram]](keyfile.png)
| Previous chapter | Index | Next chapter |
The Random access files described in the previous chapter let you pick out information from the file in any order, so they could well be used to store data bases such as address lists, personnel files etc. However, Mallard BASIC offers a very much better way of storing data bases - Keyed access files.
The problem with using Random access files for data bases is that they work in the same way as arrays. To pick out a particular piece of information, you need to know its number in the file - just as you have to know which element of an array contains the value you want. This method of selection is fine when the items of information are arranged in a nice tidy order or there are few enough items of information that you can search through until you find the information you want, but it is not very practical when you have the amount of data you typically find in a data base. Then, your only hope of finding a piece of information is by keeping an index.
Creating and maintaining an index this way is not a simple task. You have to set up a separate file to hold the index and then arrange for your program to search through the current index, sort new entries into alphabetical order, merge them with the existing index, and store the new version of the index each time you added anything to the data base.
With Keyed access files, an index is automatically created and maintained for you. Moreover, these files use a very sophisticated type of index called a B*-tree which reduces the amount of effort your computer has to make to find a record. It also ensures that your records are sorted into alphabetical order of keyname: you don't need to have a special (complicated) sorting program to do this for you.
To pick out pieces of information from a Keyed access file, you simply quote one or more of the 'Keys' that have been associated with the information you want. For example, if the data file is an address list, you might have chosen to tag Fred Smith's address in Yorkshire with the keys 'Smith' and 'Yorkshire' - so that you can pick out the full information by telling BASIC to look for Smith or Yorkshire, or both Smith and Yorkshire as appropriate.
Each Keyed file is actually two files: a Data file and an Index file. The Data file is essentially a Random access file, holding allyour information. The Index file is a special file that holds all the keys in up to eight different indexes, known as Ranks. Mallard BASIC lets you deal with the Data file and the Index file as though they were one file.
We can represent the Data and Index files as follows:
Each entry in the Index file just consists of the key value itself plus a pointer to the appropriate record in the Data file - the record number. An individual index entry can only point to one data record, but a number of index entries can point to the same data record.
Programs involving Keyed files use standard BASIC commands to control how the program works, but special 'Jetsam' commands to read and write the Keyed files. In fact, many of these commands are special versions of standard BASIC file handling commands - OPEN, GET, PUT, CLOSE etc. The extra commands that are involved are ones to flip through the index to see what's there.
The actual order of the records in the Data file never affects how you use a Keyed file because you never search through the data file itself; all your searching is through the index. It is the order of the keys in the Index file and the fact that the keys are in alphabetical order that are important.
The last key that was looked up in the Index file and the record that this pointed to have an important role in Keyed file handling. Together they define the Current position in the Keyed file. When you design a program that uses a Keyed file, it helps to be aware of how the Current position will change as you work through the program. As a rule, changes to the Keyed file are made at the Current position and so a number of the special Jetsam commands either need you to set the Current position first or change it themselves.
The commands that work with Keyed files all require you to set a 'lock'. This tells BASIC whether you want exclusive use of a file (or of a particular record) or whether other users may read the file while you are working on it. The lock is only needed for multi-user systems where you could have a number of people wanting to use the same file at the same time. It is included in all versions of these commands so that programs can readily be transferred between single-user and multi-user systems. In this chapter, we will be simply specifying exclusive access to both files and records because a program that uses exclusive locks throughout will work in the same way on a multi-user system as on a single-user one. How to use locks on multi-user systems is described in 'Mallard BASIC: Introduction and Reference'.
Any program in which Keyed files are used has three main stages:
This final closing stage might seem a refinement but it is in fact very important. The way Keyed files are handled means that there are times when the Index and Data files stored on disc are slightly out of step. If you were to stop at that point, your data base would no longer be correct. When the file is closed correctly, both files are brought fully up to date. Rather than let you pull the wrong information out of the data base (probably unnoticed), BASIC won't let you use a Keyed file that wasn't correctly closed the last time it was used - so be careful!
To illustrate how to write these different parts of the program, we shall now write a simple data base program that reads an address list keyed by name, adds new entries and deletes entries that are no longer required. So that the Keyed file handling isn't obscured, the program won't worry about vetting the input or any of the other refinements that you might build into a 'real' program.
Don't worry if you don't understand all the elements of this program. You will still get a good idea of how to go about the task and the example can be used as a model for when you want to write your own data base program.
Note: Data base programs as a rule work with existing files and so you need to use a separate program to set up the Keyed file in the first place. This program just has to create the Keyed file, defining the length of the records in the file, and then close the file again. (The process of creating the file also opened it.)
Our example program uses a Keyed file made up of the Index file ADDRESS.KEY and the Data file ADDRESS.DAT. The program to create this Keyed file would be:
10 file%=1: recleng%=122 : lock%=2 20 CREATE #file%, "ADDRESS.DAT", "ADDRESS.KEY", lock%, recleng% 30 CLOSE #file% 40 END
Here file% is the file number (ie. the number that will be used to refer to the
file for the remainder of this program) and recleng% is the length (in bytes) of
the records we will be using in the file. The lock% may be set to 0, 1 or 2,
corresponding to the different types of lock that can be applied to a file. The lock we set here,
2, specifies exclusive access to the file and is the one we recommend using on single-user systems.
Type in this program, use it to create the new files (on the disc in the current default drive) and then save the program - for example as NEWADDR.BAS. You may need this program again while you are developing the main program: if there are any problems while you are testing the program, you may have to delete the Index file and Data file and then use your NEWADDR program to create a new Keyed file.
The program will simply:
This requires a very straightforward main program, using subroutines to:
The main program we need is:
100 '
110 ' Preparatory stage
120 ' =================
200 PRINT "This is where we set aside some memory used for
manipulating Keyed files, open the Address file
and define the record layout"
300 '
310 ' Main Program Loop
320 ' =================
400 INPUT "Add, Read, Delete or Quit: Type
initial letter "; keyread$ : keyread$=UPPER$(keyread$)
500 IF keyread$="A" THEN GOSUB 3000 ELSE IF keyread$="R"
THEN GOSUB 4000 ELSE IF keyread$="D" THEN GOSUB 5000
600 IF keyread$ <> "Q" GOTO 300: REM Loop until "Q" is typed
700 '
710 ' Close Address file
720 ' ==================
800 PRINT "This is where we close the Keyed file, ensuring
that the Index file and Data file on disc are correctly
up to date"
900 END
We will now fill out this program with the details of the preparatory and closing stages and of the subroutines.
The first stage of any program using Keyed files must do three things:
The command to use is the BUFFERS command and the space you allocate sets the limit on the amount of the index that can be held in memory at any one time.
Space is available in 'buffers' of 128 bytes and the number of units you specify depends on whether you are more worried about the speed at which the program works or the amount of space available to your program as a whole. The more buffers you specify the faster Keyed files can be searched, but the space available to your program is reduced by 128 bytes per buffer. Six is usually a good number to start with, giving you the statement:
210 BUFFERS 6
The command we want here is:
OPEN "K", #file%, "ADDRESS.DAT", "ADDRESS.KEY", lock%, recleng%
This opens the existing Keyed file pair ADDRESS.DAT (the Data file) and ADDRESS.KEY (the Index file).
The command contains some special elements:
"K"which means this is the Keyed version of the OPEN command
file%which is the number that will be used to refer to this Keyed file wherever it is used in this program
recleng%which holds the length of a name and address record
lock%which may be set to 0, 1 or 2, corresponding to the different types of lock that can be applied to a file: the lock we recommend you to use on single-user systems is 2 which gives you exclusive use of the file.
In our example, keyfile% will be 1 and recleng% will be 122
(20 for the name, five lots of 20 for the address and an extra 2 bytes that you always have
to add to the total). These values stay the same throughout the program so you could write
them directly into the OPEN command, but this would make the program harder to read and harder
to update. It is better to have four statements:
220 file%=1: recleng%=122: lock%= 2 230 OPEN "K", #file%, "ADDRESS.DAT", "ADDRESS.KEY", lock%, recleng%
Before you can either read records or add new records to the data file, you have to use a command to define the layout of these records in the data file and assign string variables to each of these fields. This is called defining the record's 'Fields'. The Data file is a Random access file and so the command used to set up the fields in it is a FIELD command, exactly as you use a FIELD command to define the layout of records in a Random access file (see Chapter 6).
This FIELD command must always be after the OPEN command but before the loop which reads and writes the records.
For the address file we want the first 20 bytes for the name and then five lots of 20 bytes for the address, giving us the FIELD statement:
240 FIELD #file%, 20 AS namefld$, 20 AS addrfld1$, 20 AS addrfld2$, 20 AS addrfld3$, 20 AS addrfld4$, 20 AS addrfld5$
Note how field variables all have individual names; they cannot be set up as members of an array.
With these commands, the first part of the program has now become:
100 '
110 ' Preparatory stage
120 ' =================
200 PRINT "This is where we set aside some memory used for
manipulating Keyed files, open the Address file
and define the record layout"
210 BUFFERS 6
220 file%=1: recleng%=122: lock%= 2
230 OPEN "K", #file%, "ADDRESS.DAT", "ADDRESS.KEY", lock%, recleng%
240 FIELD #file%, 20 AS namefld$, 20 AS addrfld1$, 20 AS
addrfld2$, 20 AS addrfld3$, 20 AS addrfld4$, 20 AS addrfld5$
300 '
310 ' Main Program Loop
320 ' =================
330 '
The subroutine that adds a record to the data base (the subroutine at 3000) has to:
The actions of reading in a new name and address and displaying this information are standard data handling operations, not involving any of the special Jetsam commands at all. Moreover, they might well be required at a number of different points in the finished program, so we shall write these as separate subroutines - at 1000 and 2000, respectively.
In outline, this gives us the following subroutine:
3000 ' 3100 ' Add a record to the database 3200 ' 3300 GOSUB 1000: REM - read in name and address 3400 GOSUB 2000: REM - display it to check it's OK 3500 INPUT "Is that correct Type Y or N "; nameok$ : nameok$ = UPPER$(nameok$) 3600 IF nameok$ = "N" GOTO 3300: REM - loop and ask again if not OK 3700 PRINT "This is where we fill the fields with the data" 3800 PRINT "This is where we add the record to the data base" 3900 RETURN
Before we go any further, it is a good idea to write the input and display subroutines at 1000 and 2000. If you have got these working, you can use them to test the Keyed file handling.
The input subroutine just needs to use INPUT statements to prompt you to type the name and then the lines of the address, and to read this information into the program. So the subroutine would be:
1000 ' 1100 ' Subroutine to read Name and Address 1200 ' 1300 LINE INPUT "Name "; pername$ 1400 FOR i% = 1 TO 5 1500 LINE INPUT "Address Line "; peraddr$(i%) 1600 NEXT i% 1900 RETURN
Similarly, the display subroutine just needs to use PRINT statements to display the name and address information on the screen:
2000 ' 2100 ' Subroutine to display Name and Address 2200 ' 2300 PRINT pername$ 2400 FOR I% = 1 TO 5 2500 PRINT peraddr$(I%) 2600 NEXT I% 2900 RETURN
Note: These subroutines use an array - peraddr$ - to store the
five lines of the address. So we must remember to put a DIM statement at the beginning of
the program as follows:
140 DIM peraddr$(5)
The Data file is a Random access file and so we use the same techniques to fill the record fields with data.
Field string variables, as we explained when describing how to use Random access files, aren't
given a value through a simple assignment statement like addrfld2$ = "address".
Instead the assignment takes one of the following three forms:
LSET field-variable = string-expression RSET field-variable = string-expression MID$ (field-variable,start,length) = string-expressionLSET - which sets the field-variable to the string-expression, left aligned and padded out with spaces - is the one we shall use here. So we shall need six LSET commands as follows:
3710 LSET namefld$=pername$ 3720 LSET addrfld1$=peraddr$(1) 3730 LSET addrfld2$=peraddr$(2) 3740 LSET addrfld3$=peraddr$(3) 3750 LSET addrfld4$=peraddr$(4) 3760 LSET addrfld5$=peraddr$(5)
Once the record has been filled, we can add it to the data base. For this, we use a special Jetsam instruction - ADDREC which both puts the record into the Data file and puts the chosen key into the Index file.
The information we need to give ADDREC is the reference number of the Keyed file and the key we want to use for the entry:
ADDREC(#file%,2,rank%,key$)
file% is the file number we are using in this program to identify the data file,
2 is (once again) the type of lock that we recommend you to use (exclusive access) and
key$ is the name the record is to be tagged with. As the index is kept in
alphabetical order, key$ also defines the place the key fits in the index. The
other item in this instruction - rank% - is the number of the index you want to
add the key to. You are allowed to put the keys associated with the records in the data base into
up to eight indexes (known as ranks), identified by the numbers 0...7.
Where, as in this example case, you are only interested in keeping one index of these keys, it is simplest just to use rank number 0. Indeed, for most practical purposes, you can think of the ADDREC instruction as:
ADDREC(#file%,2,0,key$)
The key you use is up to you. The only restriction is that it is no more than 31 characters
long. In a simple address file, the obvious thing to use to tag each record is the name, so we
will use pername$ as our key.
ADDREC, in common with the other special Jetsam instructions, is a function rather than a command - that is, it produces a value as well as performing the task. The Jetsam instructions are set up like this because in some cases BASIC won't be able to execute your instruction - for example, the command that deletes keys will fail if the key cannot be found.
The value the instruction produces - known as the return code - gives you a way of checking that all is well. In general, a return code of zero indicates succaess, while a non-zero return code indicates failure. Thus the ADDREC statement we want is:
3810 rc%=ADDREC(#file%,2,0,pername$)which we should follow with a test of whether the command was successful. To keep this example program simple, we will just display a message on the screen when the ADDREC fails - as follows:
3820 IF rc% <> 0 THEN PRINT "ADDREC FAILED,Return Code "; rc%
That completes the task of adding a record to the database, making the completed subroutine:
3000 ' 3100 ' Add a record to the database 3200 ' 3300 GOSUB 1000: REM - read in name and address 3400 GOSUB 2000: REM - display it to check it's OK 3500 INPUT "Is that correct? Type Y or N "; nameok$ : nameok$=UPPER$(nameok$) 3600 IF nameok$ = "N" THEN GOTO 3030: REM loop again if not OK 3700 PRINT "This is where we fill the fields with the data" 3710 LSET namefld$ = pername$ 3720 LSET addrfld1$ = peraddr$(1) 3730 LSET addrfld2$ = peraddr$(2) 3740 LSET addrfld3$ = peraddr$(3) 3750 LSET addrfld4$ = peraddr$(4) 3760 LSET addrfld5$ = peraddr$(5) 3800 PRINT "Add the record to the data base" 3810 rc% = ADDREC (keyfile, 2, 0, pername$) 3820 IF rc% <> 0 THEN PRINT "ADDREC FAILED, Return Code "; rc% 3900 RETURN
Looking up a record in the data base is split into three stages:
In outline, this gives us the following for the subroutine at 4000:
4000 ' 4100 ' Retrieve record from database 4200 ' 4300 PRINT "This is where we locate the record" 4400 PRINT "This is where we get the record" 4500 PRINT "This is where we extract the data" 4600 GOSUB 2000: REM - display the data 4900 RETURN
This uses another special Jetsam instruction - SEEKKEY(#file%, 2, rank%, key$)
which searches the Index file for the key you specify.
Again, file% is the file number we are using to identify the data file,
2 is the lock we suggest you set (exclusive access), rank% is the number of
the index that you put the key in, and key$ is the name you tagged the record
with. In this simple program, we are just using one of the eight possible indexes - rank number 0 -
so the instruction we want is:
SEEKKEY(#file%,2,0,key$)
SEEKKEY, like ADDREC, is a function rather than a command, producing a return code so that you can see whether the operation was a success or a failure. Once again, a zero return code means success while a non-zero code indicates failure for some reason and the program needs to test whether the operation was successful. As with ADDREC, we will keep the program simple and just use the statements:
4320 rc%=SEEKKEY (file%,2,0,key$) 4330 IF rc%<> 0 THEN PRINT "Failed to find ";key$, "Return Code ";rc%: RETURN
The only thing that is missing at this point are details of the key SEEKKEY is to search for. This has to be typed in, so the program needs an INPUT statement to prompt you to do this:
4310 INPUT "Type name to look up: ";key$
Note: BASIC won't be able to find the entry you require unless you type in the key using exactly the same combination of capital and lower case letters as was used when the key was set up. Extra trailing spaces after the key name will also stop the key from being found. However, your program can be designed to force all the keys into a particular style (eg. all capitals, no extra spaces) which will overcome this problem.
Using SEEKKEY looks up the Index file and finds the record number for the record in the Data file - rather like you might look up a topic in the index of a book and find out the number of the page it is described on. SEEKKEY doesn't actually read the record. Before you can read the information, you need to Get the relevant record from the file, just as you have to Get records from Random access files.
To get the record, we use the standard BASIC command GET.
This command generally needs to be told precisely which part of the file to get, but we can use the simple version of the command which gets the Current record. The SEEKKEY command we have just used changed the Current position to the key and record it found in the index. So all we need here is:
4410 GET file%
Note: This simple form of the GET command is also available for getting information from Random files but then it gets the record following the current record, rather than the current record itself - a subtle but important difference.
The GET command used above associates the information in the record with the field-variables defined in the FIELD statement at the beginning of the program. To use the information, you need to extract the data into standard program variables.
Extracting the data is like filling the fields with new information, but in reverse. But the process is simplified because ordinary assignment statements can be used:
4510 pername$=namefld$ 4520 peraddr$(1)=addrfld1$ 4530 peraddr$(2)=addrfld2$ 4540 peraddr$(3)=addrfld3$ 4550 peraddr$(4)=addrfld4$ 4560 peraddr$(5)=addrfld5$
To display the information, we can use the same subroutine that we used to help check that the information we were about to add to the Data file was correct - the subroutine at 2000, giving the line:
4600 GOSUB 2000: REM - Display the record
Thus the complete subroutine:
4000 ' 4100 ' Retrieve record from database 4200 ' 4300 PRINT "This is where we locate the record" 4310 INPUT "Type name to look up: ";key$ 4320 rc%=SEEKKEY (file%,2,0,key$) 4330 IF rc%<> 0 THEN PRINT "Failed to find ";key$, "Return Code ";rc%: RETURN 4400 PRINT "This is where we get the record" 4410 GET file% 4500 PRINT "This is where we extract the data" 4510 pername$=namefld$ 4520 peraddr$(1)=addrfld1$ 4530 peraddr$(2)=addrfld2$ 4540 peraddr$(3)=addrfld3$ 4550 peraddr$(4)=addrfld4$ 4560 peraddr$(5)=addrfld5$ 4600 GOSUB 2000: REM - display the data 4900 RETURN
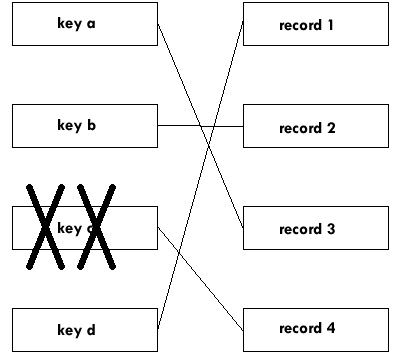
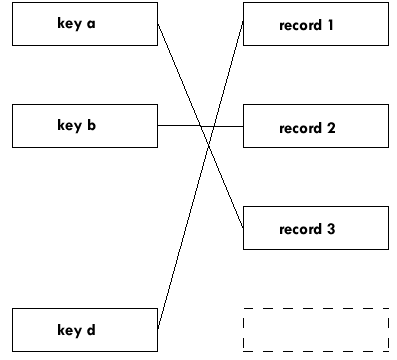
BASIC works its way around a Keyed file by finding the key in the Index file and then changing its Current position in the Keyed file to the combination of key and record it finds. If there is no key associated with a record, BASIC will never go to the record: it is as if the record does not exist. So the way to delete an entry from a Keyed file is simply to delete all the keys associated with the record.
| Delete the key ... | and the record is deleted too: |
 |
 |
The data in the record initially remains in the file, but the next time a record is added, BASIC may well use that 'empty' slot for the new data.
The subroutine that deletes an entry must:
The simplest way to do this is to use our 'Read' subroutine to retrieve the record and then use a special Jetsam command - DELKEY - to delete the key.
The DELKEY command has two different forms: the simpler deletes the Current key (the Current position then moves to the next key and record in the index); the other deletes a specified key (leaving the Current position unchanged - unless, of course, you specified the Current key!). The effect of the 'Read' subroutine is to make the retrieved key the Current key, so we can use the simpler form of DELKEY:
rc%=DELKEY(#file%,2)
As usual, file% is the number we have associated with the Keyed file, 2 is the
lock that we recommend and rc% is the return code produced by the Jetsam function
to show whether the instruction was successful. However, in this case, a non-zero return code can
mean success - up to 103. To avoid confusion in other parts of the program, the statement that
checks whether the command was successful will also set all 'success' return codes to zero.
The subroutine we will use to delete the record is therefore:
5000 ' Delete a record from the data base 5200 ' 5300 GOSUB 4000: REM - look up the record to delete 5400 IF rc%<>0 THEN RETURN: REM - exit if look-up failed 5500 rc%=DELKEY(#file%,2): REM - delete the current record 5600 IF rc%>103 THEN PRINT "Record not deleted" ELSE rc%=0 5900 RETURN
After you have finished with a Keyed file, you must close it. This does two things:
If the files aren't properly closed, there is a risk that the Index file and the Data file stored on disc are inconsistent, with the result that the data base could give you incorrect results in future. Rather than let this happen, BASIC won't let you use a Keyed file unless you closed it properly the last time.
The command that does this CLOSE and the statement we will use is:
810 CLOSE #file%
100 '
110 ' Preparatory stage
120 ' =================
200 PRINT "This is where we set aside some memory used for
manipulating Keyed files, open the Address file
and define the record layout"
210 BUFFERS 6
220 file%=1: recleng%=122: lock%= 2
230 OPEN "K", #file%, "ADDRESS.DAT", "ADDRESS.KEY", lock%, recleng%
240 FIELD #file%, 20 AS namefld$, 20 AS addrfld1$, 20 AS
addrfld2$, 20 AS addrfld3$, 20 AS addrfld4$, 20 AS addrfld5$
300 '
310 ' Main Program Loop
320 ' =================
330 '
400 INPUT "Add, Read, Delete or Quit: Type initial letter ";
keyread$ : keyread$=UPPER$(keyread$)
500 IF keyread$="A" THEN GOSUB 3000 ELSE IF keyread$="R"
THEN GOSUB 4000 ELSE IF KEYREAD$="D" THEN GOSUB 5000
600 IF keyread$ <> "Q" THEN GOTO 300: REM Loop until "Q" is typed
700 '
710 ' Close Address file
720 ' ==================
730 '
800 PRINT "This is where we close the Keyed file, ensuring
that the Index file and Data file on disc are up to date"
810 CLOSE #file%
900 END
1000 '
1100 ' Subroutine to read Name and Address
1200 '
1300 LINE INPUT "Name "; pername$
1400 FOR i% = 1 TO 5
1500 LINE INPUT "Address Line "; peraddr$(i%)
1600 NEXT i%
1900 RETURN
2000 '
2100 ' Subroutine to display Name and Address
2200 '
2300 PRINT pername$
2400 FOR I% = 1 TO 5
2500 PRINT peraddr$(I%)
2600 NEXT I%
2900 RETURN
3000 '
3100 ' Add a record to the database
3200 '
3300 GOSUB 1000: REM - read in name and address
3400 GOSUB 2000: REM - display it to check it's OK
3500 INPUT "Is that correct? Type Y or N "; nameok$ : nameok$=UPPER$(nameok$)
3600 IF nameok$ = "N" THEN GOTO 3030: REM loop again if not OK
3700 PRINT "This is where we fill the fields with the data"
3710 LSET namefld$ = pername$
3720 LSET addrfld1$ = peraddr$(1)
3730 LSET addrfld2$ = peraddr$(2)
3740 LSET addrfld3$ = peraddr$(3)
3750 LSET addrfld4$ = peraddr$(4)
3760 LSET addrfld5$ = peraddr$(5)
3800 PRINT "Add the record to the data base"
3810 rc% = ADDREC (keyfile, 2, 0, pername$)
3820 IF rc% <> 0 THEN PRINT "ADDREC FAILED, Return Code "; rc%
3900 RETURN
4000 '
4100 ' Retrieve record from database
4200 '
4300 PRINT "This is where we locate the record"
4310 INPUT "Type name to look up: ";key$
4320 rc%=SEEKKEY (file%,2,0,key$)
4330 IF rc%<> 0 THEN PRINT "Failed to find ";key$, "Return Code ";rc%: RETURN
4400 PRINT "This is where we get the record"
4410 GET file%
4500 PRINT "This is where we extract the data"
4510 pername$=namefld$
4520 peraddr$(1)=addrfld1$
4530 peraddr$(2)=addrfld2$
4540 peraddr$(3)=addrfld3$
4550 peraddr$(4)=addrfld4$
4560 peraddr$(5)=addrfld5$
4600 GOSUB 2000: REM - display the data
4900 RETURN
5000 ' Delete a record from the data base
5200 '
5300 GOSUB 4000: REM - look up the record to delete
5400 IF rc%<>0 THEN RETURN: REM - exit if look-up failed
5500 rc%=DELKEY(#file%,2): REM - delete the current record
5600 IF rc%>103 THEN PRINT "Record not deleted" ELSE rc%=0
5900 RETURN
Note: This program contains a number of PRINT statements that simply display a message about the part of the program that is about to be used. Such statements are useful when you are developing the program as a way of checking that control is being transferred around the program in the way you expect - especially when some parts of the program exist only in outline. When the program is fully working, convert these statements into comments - by inserting ' at the beginning of each statement.
Many desirable features have been left out of this program. It doesn't allow you to change an entry in the data base if, for example, someone moves house. It also doesn't allow you to change the key that you are using for an entry, or to index records under a number of keys, and if you had tagged more than one entry with the same key (two Mr Smiths, say), it would only find the one that has been in the data base longest.
To illustrate how to give your program these features, we will now prepare appropriate subroutines for each of these tasks.
Each key in the Index file is associated with just one record but each record can be tagged with any number of keys, either in the same index or in different indexes.
The ADDREC instruction you use when you add the record to the data base lets you tag the record with one key. Further keys are added one at a time with ADDKEY instructions. These extra keys can be added to any one of the eight indexes or 'Ranks' that are available in each Index file. They don't have to be added to the same Rank as the original key.
Before you can use ADDKEY to add extra keys, you need to know the record's record-number. If your program adds these extra keys immediately after the ADDREC that wrote the record, the record you want will be the Current record and you can use another Jetsam instruction - the FETCHREC instruction - to discover its record-number. When your program is going back to information that was stored earlier, you need to retrieve the record first (making it the Current record) and then use FETCHREC to tell you its record-number. (If in doubt, retrieve the record, because then you can check that you are picking out the right information.)
If we were to add such a subroutine at 6000, it would be:
6000 '
6010 ' Subroutine to add extra keys to one record
6020 '
6100 GOSUB 4000: REM - retrieve record using existing
subroutine, which also displays the retrieved information"
6200 rec.no = FETCHREC(#file%): REM - remember record number
6300 INPUT "Type the new key. If no more keys to add, just press RETURN ";newkey$
6310 IF newkey$="" THEN RETURN: REM - exit subroutine when no more keys to add
6400 INPUT "Type the number of the index you want to add the key to (0..7) ";rank%
6500 rc% = ADDKEY(#file%,2,rank%,newkey$,rec.no): REM
- add the new key in the specified index
6510 IF rc% >= 130 THEN PRINT "ADDKEY failed. Operation
abandoned": RETURN: REM - exit subroutine as ADDKEY unable to add to this record
6520 IF rc% <> 0 THEN PRINT "Key not acceptable"
6600 GOTO 6300: REM - loop to add further keys
6900 RETURN
The operation of this subroutine should be clear from the comment statements. As usual,
file% is the number we are using to refer to the Keyed file and 2
is the lock we recommend.
To change the key that a record has been tagged with, you have to both add a new key (using ADDKEY) and get rid of the old key (using DELKEY).
The order in which you do these operations is important. You must add the new key before you delete the old key. If you delete the old key first and it is the only key, you will delete the record as well. We earlier used precisely this effect to delete records from the data base!
The subroutine we need uses very much the same statements as the subroutines to Add an extra key and to Delete a record. In fact, you could just make your program call first the Add key subroutine and then the Delete one. However, this wouldn't be a very good solution because each subroutine would start by using the Read a record subroutine to search the Index for the same key. A better program would search for the key once and remember the details it finds.
To keep the program simple, we will just have a subroutine that changes a key in the first index (rank 0):
7000 '
7010 ' Subroutine to Change a key
7020 '
7100 GOSUB 4000: REM - look up record to change
7200 rec.no = FETCHREC(#file%): REM - remember record number
7300 INPUT "Type the new key "; newkey$
7400 rc% = ADDKEY(#file%,2,rank%,newkey$,rec.no): REM
- add the new key in the specified index
7500 IF rc% = 0 THEN rc% = DELKEY(#file%,2,0,key$,rec.no): IF
rc%<=130 THEN rc% = 0 : REM - Delete old key and tidy rc%
7600 IF rc% <> 0 THEN PRINT "Changing key value failed, Return code = ";rc%
7900 RETURN
Notice the form of the DELKEY instruction we have used here -
DELKEY(#file%,2,0,key$,rec.no). This has more paramters than the DELKEY
we used earlier - the index we are pointing to (rank 0), the old key and the record number
the key points to. We have to specify both the key and the record-number as there could be
two different records that are tagged with the same key - for example, two different Mr Browns.
We have had to use the longer form of the DELKEY command because the key we want to delete is no longer the Current key because the ADDKEY command moved the Current key to the new key. If we had used the simpler form of DELKEY, we would have deleted the key we had just added!
The simplest sort of change to make is to change the details of the record without affecting the key the record is tagged with - the kind of change involved when someone moves house. The subroutine that makes such a change has to:
In outline, the subroutine we need is:
8000 ' 8010 ' Change a record in the data base 8020 ' 8100 GOSUB 4000: REM - retrieve record and read it 8200 ' 8210 ' Read in the new information and display it 8220 ' 8230 GOSUB 1000: REM - read in the new information 8240 GOSUB 2000: REM - display it to check it's OK 8250 INPUT "Is that correct? Type Y or N ";nameok$ : nameok$=UPPER$(nameok$) 8260 IF nameok$ = "N" THEN GOTO 8230:REM ask again if not OK 8300 ' 8310 ' Set up the new record fields 8400 ' 8410 ' Save the new information to disc 8420 ' 8900 RETURN
The process of setting up the new record fields use the same commands as we used when adding a completely new record to the data base:
8330 LSET namefld$ = pername$ 8340 LSET addrfld1$ = peraddr$(1) 8350 LSET addrfld2$ = peraddr$(2) 8360 LSET addrfld3$ = peraddr$(3) 8370 LSET addrfld4$ = peraddr$(4) 8380 LSET addrfld5$ = peraddr$(5)
As we are just changing information stored in the record, we can use a PUT command to write the new information to disc. Like GET, this command usually needs to be told whereabouts on the disc the information has to be written, but as the record in question is the Current record we can use the simple form:
8430 PUT #file%
Note: This simple form of the PUT command is also available for getting information from Random files but then it writes the record following the current record, rather than the current record itself - a subtle but important difference.
The complete subroutine is therefore
8000 ' 8010 ' Change a record in the data base 8020 ' 8100 GOSUB 4000: REM - retrieve record and read it 8200 ' 8210 ' Read in the new information and display it 8220 ' 8230 GOSUB 1000: REM - read in the new information 8240 GOSUB 2000: REM - display it to check it's OK 8250 INPUT "Is that correct? Type Y or N ";nameok$ : nameok$=UPPER$(nameok$) 8260 IF nameok$ = "N" THEN GOTO 8230:REM ask again if not OK 8300 ' 8310 ' Set up the new record fields 8330 LSET namefld$ = pername$ 8340 LSET addrfld1$ = peraddr$(1) 8350 LSET addrfld2$ = peraddr$(2) 8360 LSET addrfld3$ = peraddr$(3) 8370 LSET addrfld4$ = peraddr$(4) 8380 LSET addrfld5$ = peraddr$(5) 8400 ' 8410 ' Save the new information to disc 8420 ' 8430 PUT #file% 8900 RETURN
The more difficult case of changing a record is when this changes the key as well as the information. For example, you might want to update your name and address list when someone gets married, changing both name (the key) and address. In such cases, there are two approaches:
The second of these approaches is simpler and easier to write. We could program it as follows:
9000 ' Change the record and key 9010 ' 9100 GOSUB 5000: REM - look up and delete old record 9110 IF rc%<>0 THEN RETURN: REM - exit if look up fails 9200 GOSUB 3000: REM - add new information 9900 RETURN
But this approach won't always work. One case when it fails is when there is more than one key indexing a particular record.
A subroutine that takes Approach 1 would cope with multiple keys and could be combined with the subroutine that we prepared above that changed just the record in the disc. You just need to remember the old key and see whether it changes when you acquire the new information. If it does, then you need to change the key as well - by using the subroutine we have prepared at 7000 to change the key (ideally modified so that the program doesn't ask for the new key twice!)
In outline, the combined subroutine would be:
8000 ' 8010 ' Change a record in the data base 8020 ' 8100 GOSUB 4000: REM - retrieve record and read it 8110 old.name$=key$:REM - remember old name (current key) 8200 ' 8210 ' Read in the new information and display it 8220 ' 8230 GOSUB 1000: REM - read in the new information 8240 GOSUB 2000: REM - display it to check it's OK 8250 INPUT "Is that correct? Type Y or N ";nameok$ : nameok$=UPPER$(nameok$) 8260 IF nameok$ = "N" THEN GOTO 8230:REM ask again if not OK 8300 ' 8310 ' Set up the new record fields 8400 ' 8410 ' Save the new information to disc 8500 ' 8510 ' Test whether name has changed; if so change key 8520 ' 8530 IF old.name$<>pername$ THEN GOSUB 7000:REM change key 8900 RETURN
The point to note about this subroutine is the way it updates the information in the record before it changes the key. Whenever you want to change both the information in the record and any keys, you must be careful to finish changing the information before you start changing the keys. You mustn't have any ADDKEY or DELKEY instructions between the GET statement that reads the old information in the file and the PUT statement that overwrites the record with the new information.
The simple 'Read a record' subroutine at 4000 asks for a key and gives you the details of the entry it finds. It doesn't give you the chance to pick out other entries that have been tagged with the same key.
When you tag a new record with the same key as an existing record, the new key is inserted into the Index immediately after the existing one. This means you can gradually build up an Index containing 'sets' of identical keys, with the oldest entry with this key at the top of the set and the newest at the bottom. For example, in an address list that included a number of Mr Smiths and a number of Mr Browns, you would have a set all with the key "Mr Smith" and a set with the key 'Mr Brown'.
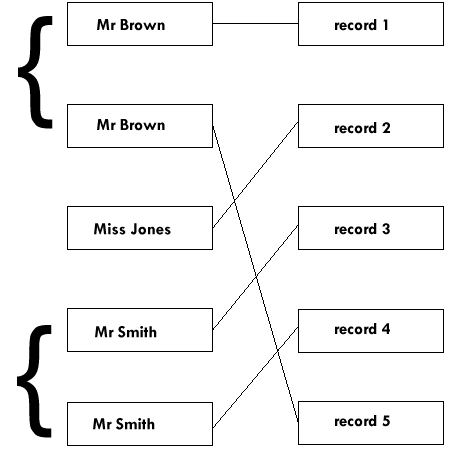
The problem with the simple Read routine is that it can only ever pick out the entry at the top of the set with this key. A better subroutine would allow you to reject this record and look at the next one in the index, so that you could gradually work through all the Mr Smiths until you find the one you want.
The Jetsam command needed here is SEEKNEXT. Once SEEKKEY has been used to find the first entry in the set, SEEKNEXT can be used to move to the next entry in the Index - which will either have the same key or the next key in the alphabetical list. (BASIC also has instructions to move to the previous entry in the Index - SEEKPREV - and to move to the next entry with a different key - SEEKSET.)
The modified subroutine should ask whether the record that is displayed is the one they wanted and, if it isn't, whether the user wants to continue searching with the same key or with a different key. If the search is to continue with the different key. If the search is to continue with the different key, the program just loops back to beginning of the subroutine - to start all over again. But if the search is to continue with the same key, the program uses SEEKNEXT to move the Current position to the next entry in the Index and then loops back to the part of the subroutine that Gets and displays the Current record.
The subroutine then becomes:
4000 '
4100 ' Retrieve record from database
4200 '
4300 PRINT "This is where we locate the record"
4310 INPUT "Type name to look up: ";key$
4320 rc%=SEEKKEY (file%,2,0,key$)
4330 IF rc%<> 0 THEN PRINT "Failed to find ";key$, "Return Code ";rc%: RETURN
4400 PRINT "This is where we get the record"
4410 GET file%
4500 PRINT "This is where we extract the data"
4510 pername$=namefld$
4520 peraddr$(1)=addrfld1$
4530 peraddr$(2)=addrfld2$
4540 peraddr$(3)=addrfld3$
4550 peraddr$(4)=addrfld4$
4560 peraddr$(5)=addrfld5$
4600 GOSUB 2000: REM - display the data
4700 INPUT "Is this the right name and address? Y or N "; nameok$ : nameok$=UPPER$(nameok$)
4710 IF nameok$="Y" THEN RETURN: REM - exit subroutine if right record found
4800 ' Determine how to continue search
4810 INPUT "Continue search with this name as the key or Try
new key. Type C or T (or other letter for neither)";
cont$ : cont$=UPPER$(cont$)
4820 IF cont$="T" THEN GOTO 4300: REM start again with new key
4830 IF cont$="C" THEN rc%=SEEKNEXT(file%,2):IF rc%=0 GOTO 4400
ELSE PRINT "SEEKNEXT failed. No more entries for this name": GOTO 4800
4900 RETURN
As with the other Jetsam commands, SEEKNEXT produces a Return code so that you can see whether the command was successful. In this case, Return codes below 103 are all successes but the program only tests for a Return code of 0 because this tells you that the entry that has been found has the same key.
The Task: The task is to provide a 'phone book' rather like the one we used in Chapter 6 to illustrate the use of sequential files, but with the following extra features:
There are three client types - 'A', 'B' and 'C'.
If you want to test your understanding of the facilities described so far, attempt to design and write the program now, without reading any further.
The design As the number of entries is large, the whole file cannot be read into an array in memory. The need to be able to access the phone book in two different ways (by name and by client type) indicates that a keyed file will be better than a random access file.
Part of the design is deciding the way that the information will be stored and keyed. The information to be stored is:
The ways in which information will be requested are:
You will need a different key for each way that information will be requested, so two ranks will be needed - one for names, one for client types. Is there any need to store this information in the data file too? This depends on whether this information will ever be needed when another key has been used to access the record and whether there is room in a key for the full data. In this example, the information will be stored as keys and in the data file.
To make the program somewhat easier to use, keys will be restricted to the first 6 characters of the name, so the user need only know the first part of the client name to find a number.
The program will consist of the following major stages:
The following description presents one way of translating these stages into a program. Many of these steps have been described already. It is left as an exercise for the reader to translate this text into a program.
| Previous chapter | Index | Next chapter |